
An automatic text labelling framework to promote digital privacy in the Android ecosystem

by Jesús Alonso, Francesca Sallicati, and Cristian Robledo (Tree Technology)
Natural language texts are still a relatively unexplored data source in the quest for digital privacy. Leveraging this, we present an automatic labelling of texts related to Android apps. This framework relies on state-of-the-art Natural Language Processing (NLP) and deep learning techniques and will be accessible from a user-friendly dashboard.
Analysing text to promote digital privacy
Unsurprisingly, digital privacy is nowadays a major issue that generates a large and frequent amount of news. National governments and trasnational organisations are legislating to preserve users’ privacy; software developers and vendors are slowly becoming aware of its relevance and improving their policies; and R&D projects, such as TRUST aWARE, aim to study the topic from every perspective and build tools to correct bad habits. As a result, new approaches to aid in the study, preservation and enforcement of privacy are continuously being explored. One of them – mainly restricted to academic environments – is the analysis of texts written in natural language related to the use of software. In the specific case of Android, natural language texts such as category, description, permissions, privacy policy and user reviews may impact on the user’s choice within the vast ecosystem of apps provided by Google Play and third-party markets. As part of TRUST aWARE, we are implementing an annotation framework for privacy policies and app descriptions of Android apps, applying state-of-the-art natural language processing and deep learning techniques, designed to improve the understanding of these documents and promote privacy in the use of apps.
Privacy policies for humans: disentangling their intricate language
Due to the General Data Protection Regulation (GDPR), every Android app is required to have a privacy policy. Privacy policies are meant to help users understand the kinds of data being collected, how they are collected, whether they will be stored and for how long, whether they will be shared to third parties or not, etc. However, privacy policies are long, boring and (sometimes deliberately) confusing documents, usually written in a specialised formal, legal language, thus being difficult to read and understand. A study even concluded that the average user would need more than 70 full-time working days to read all the privacy policies of the services used in a single year! [1] Consequently, most users would not bother to try reading them and would agree blindly with whatever is asked. To effectively help consumers to better understand how their information is collected and used, the TRUST aWARE NLP framework aims to identify the kinds of personal information being collected and the use the companies make of it, within segments of the privacy policies.

Methodologically, the process relies on different techniques. First of all, the text of the privacy policy is segmented into semantically coherent fragments by means of the Graphseg algorithm [2]. For every segment, a numerical representation of its words is calculated using FastText word embeddings [3]. Improving from previous word embedding models, such as word2vec, FastText is able to calculate representations of out-of-vocabulary words from subword information like n-grams. For this case, we have trained the word embedding model from a large corpus of unlabelled privacy policies. Finally, two convolutional neural network models are in charge of labelling each segment with its corresponding personal information types and privacy practices or uses [4].
In addition to serving as an aid to better understand privacy policies, this NLP-based inspection of contractual documents will help identify inconsistencies between user privacy expectations and the actual software behaviour inferred from static and dynamic analysis.
Assessing description-to-permission fidelity
To meet user expectations and to set adequate boundaries of behaviors, Android protects privacy-critical device functionality. Whenever an app requires access to the camera, microphone or other sensitive features, users are requested to grant permission accordingly. From the privacy and security point of view, if the functionality of an app is detailed in its description, then the request to enable the corresponding permissions would be well understood, what is known as description-to-permission fidelity [5]. This would also contribute to exposing malware and privacy-invasive apps that claim more permissions than their described functionality warrants. Addressing this issue, the TRUSTaWARE NLP framework will also be able to infer a series of dangerous permissions [6] required by the functionality described in app descriptions. This allows to contrast these to the actual permissions requested by the app and, if they do not match, arise suspicion that it could be malicious.
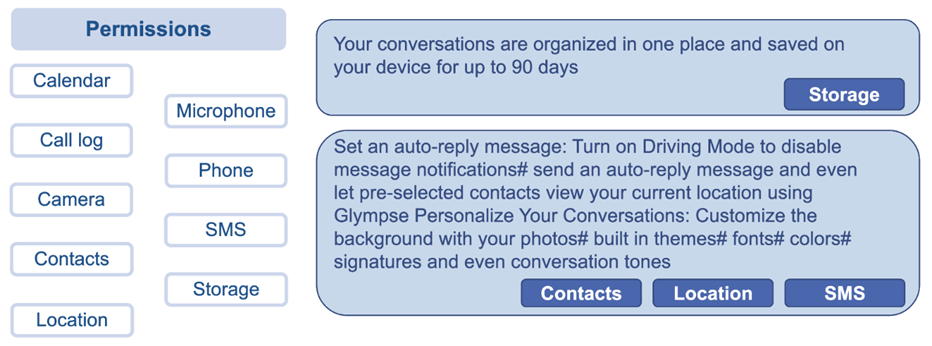
The methodology used to build this second detector is similar to the one for the analysis of privacy policies. Nevertheless, in contrast to privacy policies, app descriptions are normally written in a simpler language, trying to keep the reader’s attention, they are direct, clearly explained and not exceedingly long. Consequently, some modifications and new techniques are needed to obtain the best-performing model. To begin with, new FastText embeddings have been trained from a large corpus of unlabelled descriptions. Moreover, this time a recurrent neural network with gated recurrent units and an attention layer constitutes the final labelling model [5].
User-friendly visualisation
We have successfully built models to analyse privacy policies and app descriptions in search for the information described in the previous sections. One of the goals of this framework is to help end users to better understand the given information when Android apps are intalled and used, and to assess whether the permissions requested by the apps are really necessary for their functionality. To effectively meet this objective, the models should be accessible from an user-friendly tool. An initial design of the dashboard will be implemented in the coming months.
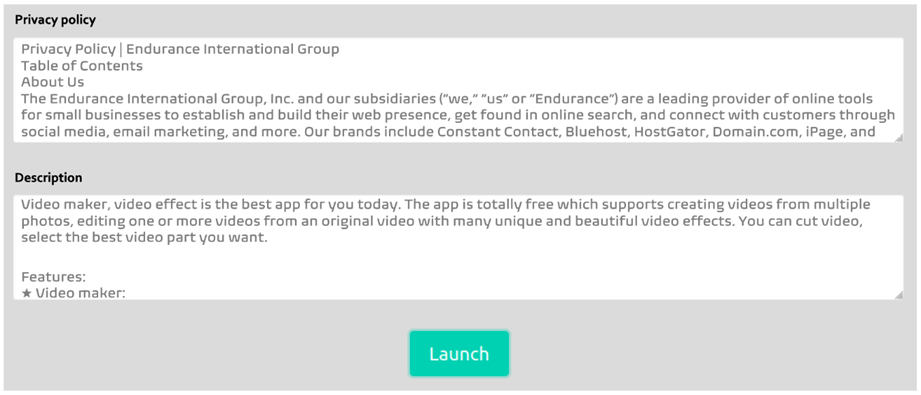

The dashboard allows the user to introduce the privacy policy and description of the app to be analysed. After the models have annotated the text, an interactive visualisation is presented. Here the user can select the category of interest (personal information types and privacy practices in the case of privacy policies, permissions in the case of descriptions) and only the segments of the document relevant to it will be shown.
What is next?
In this post, we describe a first set of services and tools for the analysis of privacy clauses in natural language texts. We will continue developing, improving, expanding and testing new ideas on the TRUSTaWARE NLP framework during the remaining two years of project, including the exploration of other software-related textual pieces like user reviews. Stay tuned!
References
[1] McDonald, A. M., & Cranor, L. F. (2008). The cost of reading privacy policies. Isjlp, 4, 543.
[2] Glavaš, G., Nanni, F., & Ponzetto, S. P. (2016). Unsupervised text segmentation using semantic relatedness graphs. In Proceedings of the Fifth Joint Conference on Lexical and Computational Semantics (pp. 125-130). Association for Computational Linguistics.
[3] Piotr Bojanowsk, Edouard Grave, Armand Joulin, Tomas Mikolov, “Enriching Word Vectors with Subword Information”, Transactions of the Association for Computational Linguistics, Vol. 5, pp. 135–146, 2017.
[4] Yann LeCun, Patrick Haffner, Léon Bottou, “Object Recognition with Gradient-Based Learning“, Shape, Contour and Grouping in Computer Vision, Vol. 1681 of Lecture Notes in Computer Science, pp. 319, Springer, 1999.
[5] H. Alecakir, B. Can and S. Sen, “Attention: There is an Inconsistency between Android Permissions and Application Metadata!”, International Journal of Information Security, vol. 20, pp. 797–815, 2021. [6] App Permission Levels Declared by Google [Online]. Available: https://developer.android.com/guide/topics/permissions/overview#normaldangerous
